An annotated single page app using React and Redux
The purpose of this book is to show how to create an isomorphic single-page-application (SPA) using React and Redux. It contains both client and server-side code to show how the client can interact with the server by using the REST API.
# The Application
It is isomorphic, meaning that on the initial load, the server can generate and provide the client with a static image of the request page with the corresponding data, which notably reduces the time a slow device, such as a tablet or smart phone, would normally require to produce the initial page.
It can also run on a desktop using Electron though no attempt has been done to exploit the desktop environment, for example, by moving the main menu from the page itself to the desktop application menu.
It is quite small, just what is required to show the main techniques described. It is, however, extensible and many other features could easily be added. Likewise, testing is scarce, just enough to show how to test the different elements in it. Though the code does work (and please let us know if it does not) the code is meant as a working sample to support this book, not to solve any real-life problem.
Unlike the many application boilerplates available (see) the intention is to fully explain what the code does so instead of a recipe to follow, this book is meant as a guide on how to build an app.
# Resources
The book and the code are available in GitHub.
Any issues with this book or the code can be reported via the projects' issues section.
# Software used
Our sample application will use JavaScript extensively both for the client and the server. We used JavaScript even for auxiliary scripts, no Bash shell or Python, all plain JavaScript.
On the client side, our application will use React along several related packages such as React-Router and Redux for data manipulation. We will use the new standard global fetch method which is already available in several browsers and can be emulated via suitable polyfills if not natively available. Its usage is concentrated on just a couple of files so it should be easy to swap it out for some other communication package.
We are using Twitter's Bootstrap for its CSS styles, fonts and icons, though we are not using any of its active components. We haven't used any active components from any library because that simply requires following the recipe for whichever library and doesn't need much explaining. We have made all of our components so as to learn how to do them.
On the server side we are using Express, possibly the most popular web server framework for Node.js. There are several other similar packages available, but this book is not about what's on the server but on the client, thus, we've made a conservative choice in this area. Express is well-known and even those who might prefer other web servers will have dabbled with Express at some point so it will be somewhat familiar. Since our application will be isomorphic, being able to run JavaScript in the server is a must.
We have used the most basic SQL database manager we could find, SQL.js a pure JavaScript version of SQLite. The concepts explained in this book are not tied to whatever data storage might be in the background so we didn't try to use anything more sophisticated. We are not advocating for any particular data storage solution and certainly not SQL.js which is quite primitive and terribly slow in a production environment, but it is very simple to install by just doing an NPM install with no need for any further setup or configuration. For the purpose of this book it takes a lot of administrative trivia out of the way and does not polute the reader's machine.
Incidentally, we are not installing anything globally, except for Node.js and a browser, both of which we would expect are already there. We are not using the -g option of the npm install command. Once done with the sample code, uninstalling it is just a matter of removing the installation folder.
We are using EcmaScript-2015 or ES6 syntax for most of the code and Babel to transpile it to ES5. We are not using ES6 for code that is not transpiled, such as ancillary scripts and the WebPack configuration files, except for some ES6 features already available in Node.js 4.4.7, the current recommended stable version.
We are using WebPack to pack our modules into bundles that a browser can load. However, since we are using ES6 syntax not yet supported by Node.js and a few other WebPack features that turn out to be quite handy, we are using WebPack to create server-side bundles as well. This is partly due to implementing isomorphism, which requires the server to be able to run the very same code that the client does so as to create the static image that the browser will download. So, it is easier if both sides use exactly the same environment.
Finally, we are using the ESLint linter with the Airbnb rules set and Mocha with expect assertions from Chai for testing.
There are plenty of other modules used here and there, but these are the main dependencies that most influence the code.
Something sorely lacking in this app are API docs. Unfortunately, none of the tools reviewed work as could be desired. Most are confused by either the JSX syntax used by React or don't support ES6 syntax or have no means to describe modules or document their exports. In the end, the resulting docs were of very little help so no effort was put into adding doc-comments to the code.
# What is where
The application ( ) contains six main folders plus those for the book itself (manuscript).
) contains six main folders plus those for the book itself (manuscript).
# The client folder
The client folder () contains all the files that will eventually get loaded in the client.
The index.jsx file sets up the React / Redux / routing environment. The .eslintrc.json file ensures the proper linting rules are used for the client-side environment.
Within it there are three further folders
# client/components
It contains the React components (). It has a couple of common files for the whole application, app.jsx contains the overall frame that will enclose the app and notFound.jsx the simple component that will show up if an erroneous, perhaps obsolete URL is provided.
We then have further folders for each of the main sections of the app. In this example we have just one such section, client/components/projects but there might well be any number of them.
Each section usually contains a routes.jsx file that states how each component is activated depending on the path in the URL. We'll see its contents later on.
# client/store
It contains the Redux components ().
The createStore.js file composes the various sub-stores into a single Redux store. The actions.js consolidates all the action and action creators (more on them later) in a single include file.
The actual stores are each in a folder underneath. For simple stores, such as misc () it is all contained in a single index.js file. For more elaborate ones such as projects () the various parts of the store are split into various files.
# client/utils
It contains various utility modules for both the React components and the Redux stores. Alternatively, a utils folder might be created in each of components and store, however, some utility functions such as initialDispatcher.js help connect both components and store so, considering that in this example we don't have that many utility modules, we've piled them up here.
# The electron folder
Turning our client/server application into a Electron desktop application isn't hard, the proof being that we've done it with just three files (). Admittedly, we haven't used any desktop-specific features such as the application menu, but doing so wouldn't be that big of an issue.
# The scripts folder
Most commands to compile, run or lint are simple enough to be contained within the package.json scripts entry so they can be run via the npm run command. A few might require some extra help. This folder might contain bash scripts or, in this case, plain JavaScript files for Node.js.
# The server folder
We will start looking at the server-side code in the very next chapter so we won't comment on the files in this folder right now. As for the folders, there is an isomorphic folder that turns the regular client/server app into an isomorphic one. Delete this folder and two lines in server.js and the application is no longer isomorphic.
The projects folder contains the server-side code to provide the data to the client-side store contained in a folder of the same name. Some of the stores on the client side do not require any server-side support, but those that do would have a folder for them.
# The test folder
It contains the scripts to test the code in each of the previous sections. Being so, it mimics the folder structure of them, there is a client folder containing a components and a store folder each containing further folders and files to test each element.
The functional folder contains a couple of functional tests. Unlike the unit tests in the previous folders, which exercise each element independently of one another, this folder contains a couple of functional tests that test the overall functionality of a complete group of elements, in this case, the web server and the REST API manipulating the data for the projects store.
The tests are not complete. We have done a few tests just to show how they can be written and which tools to use, but there is not one test for each and every element in the app.
The utils folder contains several handy modules to help in testing.
# The webpack.config folder.
Since we use WebPack to package all the bits and pieces of our app and we need several configuration files for the various environments, we placed them all in a single folder. Thus we have one for development, one for production and one for testing. They all share the common.js configuration.
# Other local folders
Once downloaded or cloned, the various scripts will create other folders which are not stored in GitHub because they are produced by the various scripts and contain no source material.
The bundles folder will contain the packages created by WebPack, transpiled by Babel and, for the production version, minified, except the one destined for the client which will be located in a publicly accessible folder.
The coverage folder will be created when the npm run coverage command is issued. It is produced by istanbul and we will look into it later.
The public folder contains whatever files might be sent to the client. This is the virtual root for any URL received from the client. Background images, icons, static pages might be contained in it. We have none of those but we do have a public/bundles folder that contains the packaged bundle destined for the client.
The tmp folder will be created by the script that executes the tests. It is deleted and rebuild every time the tests are run. It might as well be deleted after the tests are successful but sometimes the web-packed files provide clues to some errors so it is best to leave them behind.
Finally, the node_modules folder contains all sorts of NPM modules as listed in package.json.
# Installation
The easiest way to get the code running in your machine is to download the ZIP file of the project from GitHub ().
For those wanting to play with it and keep a copy of their changes in GitHub, making a fork and then cloning it locally might be a better option. If you know what the previous sentence meant, you probably know how to do it.
The application only needs Node.js installed, which also installs NPM.
Once expanded into any folder of your choice, move to that folder and do a 'npm install' which will read all the dependencies from package.json and install them. This will take a while. There are no global dependencies in the project so the installation should not mess up with any folders outside of the project, except for the cache NPM maintains of the modules it downloads. The command npm cache clean flushes it but otherwise, NPM takes care of it.
# Available commands
Once in the root folder of the project, the following commands are available.
npm run buildCreates the developer versions of the bundles that can be executed. This is the first command to run since very little of the code can be executed as-is.npm run productionCreates the production versions of the same files. The extra code used for internal checking within React is dropped and everything is minified.npm run watchSame asnpm run buildbut WebPack remains loaded in the background and whenever any of the source files changes, the corresponding bundles will be re-created.npm startStarts the web server. A browser can then access the application by going to the URL that is shown in the console. Requires the application to be built.npm run debugRuns the web server in debug mode. This command does require the node-inspector package to be installed globally and works with Chrome and Opera only.npm run lintRuns ESLint on all the source code.npm tRuns tests on the code.npm run coverageRuns the tests with code coverage via Istanbul.npm run electronRuns the Electron desktop version of this application. Requires the application to be built.npm run updateModulesUpdates NPM modules to their latest versions.
# Conventions
# OctoCats
Within the book we will use the OctoCat icon () to refer to code located in GitHub. The OctoCat is GitHub's mascot. It usually points to large stretches of code that aren't worth including along the text, but that can be looked at, if so desired.
Most of the code boxes within this book (the ones with a thick silver frame) are extracted automatically from GitHub and the original can be reached by clicking on the OctoCat icon in the frame. For example:
const NotFound = props => (
<div>
<h1>Not found</h1>
<p>Path: <code>{props.location.pathname}</code></p>
</div>
);# Predefined Constants
The code contains constant literals written in upper case characters, for example, REST_API_PATH. These are replaced by actual values during bundling, thus, REST_API_PATH will show as ("/data/v2") in the packaged bundles.
# Virtual import paths
The path to some of the imported modules start with an underscore, for example, import routes from '_components/routes';. These are virtual paths that WebPack will resolve to actual locations based on the aliases set in the configuration file (). Since an actual NPM module name cannot start with an underscore, there is no risk of name collision. These virtual routes allow us to avoid relative references to modules starting with double dot from '../../etc' which are hard to follow or maintain should files be moved relative to one another. With full paths starting from these virtual roots, any reference to a moved file can be easily located and replaced.
# Omitting extensions
We omit the .js or .jsx extensions on references to imported files. This serves several purposes. The importer should not care whether the file does contain JSX code or not. Should the contents of the file change to include some JSX syntax and, following convention, the file extension changed to .jsx, the files that import it don't need to be changed. Also, if the source file gets too large and it needs to be broken up, it can easily be done without affecting the files that import it. For example, if the file whatever.js which we import with import whatever from './whatever' needs to be split into various files, we can move whatever.js to a new folder as whatever/index.js and all the imports will still work. Then, the whatever/index.js file can be broken into several files, all within that folder, without polluting the parent folder, as long as the exports remain within index.js or are re-exported from it.
# Promises
We use Promises extensively, to the point of converting some Node.js library functions from using the callback convention into a Promise. We have mostly used denodeify to do that so that this code:
import fs from 'fs';
fs.readFile('./foo.txt', 'utf8', (err, data) => {
if (err) throw err;
// do something with data
})
Turns into this:
import fs from 'fs';
import denodeify from 'denodeify';
const readFile = denodeify(fs.readFile);
readFile('./foo.txt', 'utf8')
.then(data => {
// do something with data
});
The latter seems a more expensive proposition but it must be considered that when several asynchronous operations are chained together, it is very easy to fall into the depths of indentation hell, with each successive operation called within the callback of the previous one while with Promises all the chain is nicely aligned and clearly visible, which helps with future maintenance. It also allows for several operations to be launched at once via Promise.all.
# The Web Server code
We start by following the standard recipe to create an instance of an Express web server using Node.js native HTTP server:
const app = express();
const server = http.createServer(app);We used app as a variable name simply because it is customary to do so. All Express documentation uses app for the express server instance, req for the incoming requests and res for the responses to it. Trying to be original might lead to confusion so it is best to stick with what is common practice.
We convert the server functions we will use into Promises by denodeifying them:
const listen = denodeify(server.listen.bind(server));
const close = denodeify(server.close.bind(server));Using denodeify with functions, as we did with fs.readFile () is straightforward. When using it on method of an object instance, we have to denodeify the function reference bound to that instance, so the method has a valid this when invoked.
The same server will both provide regular HTML, style sheets, images, icons or whatever clients request but it will also manipulate data via a REST API. In a large installation, handling data might be delegated to other set of servers, while a further set of servers might actually run the database management system. We are doing it all from the same server. We are, though, creating a separate router to handle the REST API requests:
const dataRouter = createRouter();
app.use(REST_API_PATH, bodyParser.json(), dataRouter);On importing Express () we renamed express.Router as createRouter which, when called, returns a new router. dataRouter will handle all the routes that start with the REST_API_PATH path which is a constant that via some WebPack magic which we'll see later, comes from package.json:
"myWebServer": {
"port": 8080,
"host": "http://localhost",
"restAPIpath": "/data/v2"
},We will use those other host and port constants elsewhere as HOST and PORT. We usually try to respect the customary naming conventions for each type of file, that is why we use host in the package.json file and HOST in the JavaScript code, but that is a matter of preference.
Thus dataRouter handles the paths starting with /data/v2. Since the data will be expected to be in JSON format but it comes as a serialized string of data, before letting it reach dataRouter, we pass it through bodyParser.json().
It is somewhat obvious why the
/datapart of the route, after all it is meant to manipulate simple data. It might not be so obvious why the/v2. Over time, the API may change in incompatible ways, however, during the transition time, both versions will be required to coexist. We could actually have adataRouterV2and an olderdataRouterV1running from the same server responding to different APIs. We control what is running on the server, but we cannot fully control what is installed or cached in the client system so it is always a good idea to tag the API with, at least, the major version number.
Another piece of middleware we might also chain before anything reaches dataRouter is one to check the user authorization to request the execution of such operation. User authentication is quite a complex issue. It is easy to log-in and out and check whether a user is logged in. However, the permissions each user is granted tells what each can see so it affects the whole user interface which would distract us from the current goal of this book.
Express checks the paths of the URLs requested against the routes in the order in which they are set in the configuration via app.use, app.get or any of the other app.method methods. That is why the routes that branch off the natural path go before the catch-all ones, the exceptions before the generic ones.
app.use('/bootstrap', express.static(absPath('node_modules/bootstrap/dist')));
app.use(express.static(absPath('public')));The express.static handler checks the file system for requested resources. Combined with Express routing it also helps to translate public, external paths to local paths. In this case, we translate any path starting with /bootstrap to node_modules/bootstrap/dist relative to the application path. The absPath function, defined elsewhere (), uses path.join to assemble a full path from the app root and the given relative path. Bootstrap is installed in our server since it is listed as a dependency in package.json (). Translating the path here saves us from moving over the files to another public location in the server. It is handy for this book and it also shows a nice feature of Express, however, it might not be efficient in actual production.
Using express.static with no route, basically means "for everything else, check here2, in this case, the /public folder in our setup. Thus, for any route not starting with either /data or /bootstrap it will try looking for a file in /public, which includes /public/bundles where the code and CSS files for this application reside.
This catch-all route would seem the end of the road for our routes. However, if the file is not found in /public then the express.static will not send a 404 Not found error, instead, it will signal the router to keep looking for further paths, only when no further routes are available the router will send the 404 error.
# Isomorphism
app.use(isomorphic);This line sets up isomorphism on the server side. The isomorphic middleware is imported () from our own code. In Express parlance, middleware is code that stands in the middle of the process of handling a request. Both bodyParser and express.static are middleware, they do their thing, parsing JSON or trying to deliver the contents of a file, and then let Express carry on with the request or, depending on the middleware, handle it by themselves. body.parser always lets requests pass through, express.static, on the other hand, if it finds the file requested, it responds to the request by itself.
Our isomorphic middleware, which we will look at in a later chapter, does something similar. It checks whether the path matches any of the routes it is configured to handle and, if so, it deals with the request by itself, otherwise, it lets it pass through.
app.get('*', (req, res) => res.sendFile(absPath('server/index.html')));When it does pass through, it falls into the line above. For any GET request that might remain, the server will send the default index.html ().
It is easy to see the difference in using isomorphism or not. By simply deleting or commenting out the line about using the isomorphic middleware, (and rebuilding the app), the application will still work. From the user point of view, though, the browser will flash. The screen will be initially blank, then once the client code executes, it will render a blank page while the data for the initial page is requested. Finally, when the data does arrive, the page will be re-rendered with the data. Since we are using sql.js for our database server, which is quite slow, the delay is noticeable, specially in the first load before anything gets cached. If we open the developer tools in the Network tab we can see that without isomorphism we have an extra request, the one for the data.
With isomorphism active, a copy of the page with all its data is sent as static HTML. There is no flash at all. The page is rendered even before the code starts executing. When the code does execute and React is about to render it, it checks the static image that was sent from the server and, if it matches what it would render, it just lets that page be. Actually, the server sends a checksum made from the generated content as a data attribute in the static page. React just needs to check this checksum against the one it would generate itself.
Though the application, as set up, works with the isomorphic middleware dropped, the client-side code will issue a warning and the tests will also produce an error because it expects isomorphism. Fully dropping isomorphism does require a few changes elsewhere.
# Start and Stop
This server module does not start on its own, instead it exports start () and stop () functions. The reason for this is that other code might want to control it so we don't want to just let it start on its own. One such code is the test suite. The tests cannot see the Server running at .... message. It has to be able to start the server and know when it is ready to be tested. That is also why both exported functions return Promises.
# Starting
The start function sets up the database server:
export function start() {
global.db = new sqlJS.Database();
return readFile(absPath('server/data.sql'), 'utf8')
.then(data => db.exec(data))We are using SQL.js, which is not recommended for a production setting, so the code presented here should not be used in such environment.
First we create an instance of an empty, memory based database. We assign this database instance to global.db so that it is accessible as db anywhere else in the whole application. To prevent ESLint complaining about our use of this db global variable, we have set its configuration file to accept it as a global, along the other WebPack generated constant literals ().
We have an empty database right now so we read the SQL statements () that will create the tables and fill them with data and then execute the whole set of statements at once.
Connecting to an actual production-grade database engine will usually be an asynchronous operation. If the selected database driver does not already return a Promise, it will have some means to signal its readiness. For example, when connecting with the MySqL driver we might use denodeify to turn it into a Promise:
var mysql = require('mysql');
global.connection = mysql.createConnection({
host : 'example.org',
user : 'bob',
password : 'secret'
});
const connect = denodeify(connection.connect.bind(connection));
const disconnect = denodeify(connection.end.bind(connection));
// later on, in start
connect().then( /* .... */ );
// and in stop
disconnect().then( /* .... */ );
# Data handlers
An application server might have to handle different sets of data for various parts of the client application. We will call them data handlers. We only have one such data handler, projects:
import projects from './projects';Don't bother looking for a server/projects.js file. We have pretended our sample data handler to be more complex than it actually is so we broke it into several source files and placed them under the server/projects folder () and, within it, we have an index.js which is what actually gets imported.
Once the database connection is established and before we allow the web server to start accepting requests, we initialize each of those data set handlers. We will assume that such initialization might be asynchronous and that each will be independent of any other thus we use Promise.all to start them all at once. The chain of promises will only continue when all of them succeed or any of them fails.
.then(() => Promise.all([
projects().then(router => dataRouter.use('/projects', router)),
]))In our simple example application, we only have one set of data for a projects/tasks application. In a real-life app, the argument to Promise.all would contain a larger array of initializers.
Each data handler will resolve to an Express router instance. In the then part, we tell dataRouter to use that router instance when the path starts with /projects. dataRouter itself is called on routes starting with /data/v2 so our projects data handler will respond to /data/v2/projects. All requests received by dataRouter have already passed through the JSON bodyParser.
# Start listening
.then(() => listen(PORT));To finish up our initialization, we finally set the server to listen for requests, using our denodeified version of server.listen.
Promises and fat arrows go well with one another. If the body of a fat arrow function is a simple expression, not a code block, its value will be returned. Using fat arrow functions in the
thenparts of a Promise produces terse code. If the body of a fat arrow function is a Promise, it will return it, leaving the enclosing Promise in a pending state. If it is a value, it will fulfill it with that value.
# Stopping
Stopping the web server is trivial in our case since the database is an in-memory one, and we have no other resources to disconnect from. Should there be any, such as the MySQL example above, this is the place to do it.
export function stop() {
return close();
}As it is, we simply close the connection using the denodeified version of server.close. We might have simply exported the close function, but in a real app, there will be more things to attend to when closing so we opted to make the stop function a placeholder for them, though right now it holds just one simple function call.
# The CLI
To actually start and stop the server from the command line, we have index.js:
import { start, stop } from './server';
start()
.then(() => console.log(`Server running at http://localhost:${PORT}/`))
.catch(err => {
console.error(err);
process.exit(1);
});
const shutdown = () => stop()
.then(() => console.log(`Server at http://localhost:${PORT}/ closed`))
.then(process.exit);
process.on('SIGINT', shutdown);
process.on('SIGTERM', shutdown);The server is started by calling the start method imported from server.js, then we show a message to the operator and make sure to catch any errors in the startup. The code in server.js had no error-catching because what we do with an error varies in between one environment and another so it is best left to the calling module.
The shutdown function calls the stop method, shows a message and finally exits. It is called from listeners for the OS signals for program termination. This ensures everything gets cleaned up, connections to database managers and whatever other resource we might be using.
# Server-side Projects Data Handler
Our projects data handler is broken into three files:
index.jscontains the initialization code and returns a Promise resolved with an Express router.transactions.jscontains the database operations that do the actual manipulation of the data in whichever DBMS system the system uses.validators.jscontains validators for all the bits of data that might be received.
Regardless of whatever client-side validation might be in place, all data received at the server must always be validated.
# Initialization
export default () =>
transactions.init()
.then(() => createRouter()
.get('/', handleRequest(
validators.validateOptions,
transactions.getAllProjects
))
.get('/:pid', handleRequest(
validators.validatePid,
transactions.getProjectById
))
.get('/:pid/:tid', handleRequest(The default export of the data handler must be a Promise which is resolved when any required initialization is done. Usually, it is the part dealing with the DBMS the one that might be asynchronous. We have concentrated all our database operations in the transactions.js file, which has an init export which returns a Promise.
Our default export should return an Express router so, in the .then part after the initialization of the transactions, we call createRouter te get a new one. A router with no routes would be of little use. Fortunately, all the routing methods, i.e. get, post and so on, are chainable so we can call all those gets, posts and puts and still return the router, though now it would have plenty of routes to handle.
The routing method functions expect a path, which might contain parameters signaled by a leading colon : and the name that will be given to that parameter. All those paths are relative to the route of our projects route, which is /data/v2/projects.
Each path can be followed by any number of middleware functions. We have used none in this case. Then, the route handler which we called handleRequest.
export const handleRequest = (...args) => (req, res) => {
const o = {
keys: req.params,
data: req.body,
options: req.query,
};
const action = args[args.length - 1];
Promise.all(args.slice(0, -1).map(validator => validator(o)))
.then(() => action(o))
.then(reply => res.json(reply))
.catch(reason => {
res.status((reason instanceof Error) ? 500 : reason.code).send(reason.message);
});
};handleRequest returns a function that will actually handle the request. It first extracts information from the request. The object o contains three main properties:
keyscontains the identifiers that help locate the data. They are extracted from the requestparams.optionswill be an object that may contain some processing options, extracted from the part of the URL after the query mark.datamay contain data required by the operation, extracted from the body, decoded bybodyParser.json()
The change of names might be considered somewhat whimsical, however, they most closely represent the purpose of each element within the transaction than the names of the parts within the URL.
handleRequest expects an arbitrary number of arguments args. All but the last are validators while the last is the one actually executing the transaction. They all receive a copy of the o object.
All the validators are launched in parallel via Promise.all, under the assumption that they are independent of one another. If any of them were not, then they should be sequenced elsewhere.
Once all validators are finished, then the action is executed. By this time, all values would have been validated and some of them converted. The action is expected to return a value (or a Promise to return one) which is then send back to the client via res.json().
The validators are not expected to return anything except, possibly, a rejected Promise. The action is expected to return data to be sent to the client but it might also return a rejected Promise. To help send those errors, the failRequest function creates a rejection:
export const failRequest = (code, message) => Promise.reject({ code, message });If any do return a rejected Promise, the last catch in the chain will receive a reason which is expected to contain a code and a message. The code should be an HTTP error code, however, any of the validators or actions might actually throw an error. So, in case of any rejection, the Promise is caught and, if the reason is an instance of Error, an 500 HTTP status code is sent back as the HTTP status code and the message as the HTTP status text. If it is not an instance of Error, then the code is sent. Both have a message property so the text is always sent.
# Validators
The function that validates project ids is a typical validator:
export function validatePid({ keys }) {
const pid = Number(keys.pid);
if (Number.isNaN(pid)) return failRequest(400, 'Bad Request');
keys.pid = pid;
}The pid (project id) is the main record identifier for projects. The client expects it to be a string, for example a UUID. In our tiny database, our ids are actually integers from an auto-incremented primary-key field. Our validator then tries to convert it into a number. If it turns out not to be a number, it fails with a 400, Bad request error. Otherwise, it saves the converted pid back into the keys property.
Other validators () work pretty much like this one, they pick different pieces of data, do some validation and possibly a conversion and either fail with an rejection or do nothing which allows the request to carry on.
We have not been particularly original with our error messages. In this implementation, the code should be a valid HTTP code which should be in the 4xx range. If there were other sources of errors that might not be instances of Error, they would have to be converted.
# Transactions
Our primitive SQL manager does require some initialization, namely preparing the SQL statements that we will use later, which is done in the init function:
const sqlAllProjects =
`select projects.*, count(tid) as pending from projects left join
(select pid, tid from tasks where completed = 0)
using (pid) group by pid`;
export function init() {
prepared = {
selectAllProjects: db.prepare(sqlAllProjects),
selectProjectByPid: db.prepare('select * from projects where pid = $pid'),
selectTasksByPid: db.prepare('select tid, descr, completed from tasks where pid = $pid'),
selectTaskByTid: db.prepare('select * from tasks where tid = $tid and pid = $pid'),
createProject: db.prepare('insert into projects (name, descr) values ($name, $descr)'),
createTask: db.prepare(
'insert into tasks (pid, descr, completed) values ($pid, $descr, $completed)'
),
deleteProject: db.prepare('delete from projects where pid = $pid'),
deleteTasksInProject: db.prepare('delete from tasks where pid = $pid'),
deleteTask: db.prepare('delete from tasks where pid = $pid and tid = $tid'),
};
return Promise.resolve();
}We use db.prepare to tell the driver to pre-compile the SQL statements so later executions will run faster. We store them all into the prepared object. We will use the text of the sqlAllProjects statement elsewhere, that is why we have it defined separately. The db variable contains the reference to the database driver we inititialized and assigned to global.db on setting up the web server (). All SQL.js operations are synchronous, however, our data handler code allows for asynchronous operations and expects a Promise so, at the end of the init function, we return a resolved Promise.
Most SQL statements listed contain identifiers starting with a $ sign. Those are placeholders for actual values that must be filled in later, when the query is actually performed.
A transaction will either return the data to be sent back to the client or a Promise to return such data or it will return Promise.reject and, of course, it may always throw an error, which also implies a rejection.
export function getTaskByTid(o) {
const task = prepared.selectTaskByTid.getAsObject(dolarizeQueryParams(o.keys));
if (!task.tid) {
prepared.selectTaskByTid.reset();
return failRequest(404, 'Item(s) not found');
}
task.completed = !!task.completed;
task.tid = String(task.tid);
task.pid = String(task.pid);
prepared.selectTaskByTid.reset();
return task;
}We retrieve a task by calling the prepared statement in prepared.selectTaskByTid. The getAsObject method retrieves the record as an object with the database column names as its property names. As an argument, getAsObject takes an object with the named placeholders, those identifiers starting with a $ sign in the statement, and their values. Since mapping the query parameters to those $ placeholders is such a common operation, we have provided a dolarizeQueryParams function () to do it for us.
Since an object is always returned, we check to see if it is empty by checking a mandatory field, task.tid. Auto-incremented SQL fields can never be zero so this is an easy and safe way to do such a test. So, if there is no tid then we return a rejection. Otherwise, we do some field conversions we return the retrieved task record. SQLite has no booleans, only 0 or non-zero integer fields, so completed must be converted. pids and tids must be converted from integers, as they exist in the database, to strings.
In either case, once used, the prepared statement must be reset to have it ready for later queries. This is an idiosyncrasy of SQL.js.
Other transactions such as getAllProjects () may potentially return too many records so we might want to limit both the number of records and/or the columns returned.
const fields = o.options.fields;
const search = o.options.search;
return fetch(
(fields || search)
? db.prepare(`select ${fields || '*'} from (${sqlAllProjects})
${search
? ` where ${search.replace(/([^=]+)=(.+)/, '$1 like "%$2%"')}`
: ''
}`
)
: prepared.selectAllProjects
);We read the fields, which contains a comma delimited list of fields to retrieve, and search which contains a column name and a value to be contained within that column. Both options have been already validated to contain only strings in that format.
If there are either search term or list of fields, instead of using the prepared.selectAllProjects prepared statement, we build one on the fly by doing some string manipulation using the sqlAllProjects SQL statement which we had set aside () on initialization.
Either way, we fetch those records in the usual SQL.js way:
const fetch = stmt => {
const projects = [];
let prj;
while (stmt.step()) {
prj = stmt.getAsObject();
prj.pid = String(prj.pid);
projects.push(prj);
}
stmt.reset();
return projects;
};The step method advances the cursor to each successive record and getAsObject does the actual reading of each record. After converting the values that need conversion, the records are pushed into the projects array which eventually gets returned.
export function getProjectById(o) {
const prj = prepared.selectProjectByPid.getAsObject({ $pid: o.keys.pid });
if (Object.keys(prj).length === 0) {
prepared.selectProjectByPid.reset();
return failRequest(404, 'Item(s) not found');
}
prepared.selectProjectByPid.reset();
return Promise.resolve(getTasksByPid(o))
.then(tasks => {
prj.tasks = tasks;
return prj;
});
}Transactions might use one another, in this case, getProjectById uses getTasksByPid. Though the latter usually returns an array of tasks, we must remember that it may return a Promise, a rejected Promise at that so, we use Promise.resolve when calling it so we ensure it does get treated as a Promise.
# React Components
React Components range from the very tiny to somewhat complex ones though never 'very complex ones'. If a single component is very complex it means it is trying to do too much thus it should be broken into several simpler components.
Each component takes care of producing a small section of the UI of an application. We need to compose them to build the whole application. We will see how several of them work, each with a higher degree of complexity.
Components can be stateless or stateful. Stateless components are made of a simple function that receives a series of arguments called properties usually abbreviated to props, and returns the expected representation of the little piece of UI it deals with.
# Stateless Components
import React, { PropTypes } from 'react';
const NotFound = props => (
<div>
<h1>Not found</h1>
<p>Path: <code>{props.location.pathname}</code></p>
</div>
);
NotFound.propTypes = {
location: PropTypes.shape({
pathname: PropTypes.string,
}),
};
export default NotFound;The NotFound component is a simple stateless component. It receives a props object which contains a bunch of information provided by the parent component, in this case the React Router. It returns very simple HTML with a text message containing the path that was not found. React Router handles navigation within a Single Page Application. It can be told which parts of the application to render depending on the URL and it can also be told what to do when no route matches the requested path. The NotFound component was configured to be used in such a case.
NotFound is written in JSX, a syntax closely associated with React but not really restricted to it, for example, MSX can be used with Mithril.
Though files containing JSX usually have a .jsx extension, this is not mandatory at all and, actually, many of our tools have to be told to read .jsx files as plain JavaScript with some extra.
JSX allows inserting HTML/XML-like code into a JavaScript source code file though, of course, the resulting mix cannot be interpreted directly as JavaScript but has to go through a compiler to produce actual JavaScript code. The compiler looks for an expression starting with a < symbol. In JavaSript, the less than symbol is a binary operator, that is, it sits in between two expressions, so no expression could possibly start with it because it would be missing the left-hand-side part. If there could be any doubt about whether a < is binary or unary, enclosing the JSX in between parenthesis disambiguates it since after an open parenthesis, there can only be an expression.
JavaScript expressions, not statements, are allowed within JSX, they have to be enclosed in between curly brackets {}.
If I may take a moment to brag about it, back towards the end of 2008 I made a proposal to embed HTML into PHP. I called it PHT which resulted from merging the letters in PHp and HTml. It was an extension to the PHP Compiler which could generate native code but could also serve as a transpiler. I used is as a transpiler to create regular PHP out of PHT code. Mechanisms to publish and make open source contributions back then were not widely available, no GitHub or any such popular sharing mechanisms, so the idea faded away.
const NotFound = props => (
<div>
<h1>Not found</h1>
<p>Path: <code>{props.location.pathname}</code></p>
</div>
);Our NotFound component receives props as an argument and, since it uses a fat-arrow function it implicitly returns what follows. It returns a <div> enclosing a heading and a paragraph showing the path that was not found. To insert the path within the JSX code, we enclose it in curly braces.
React provides a mechanism to ensure the properties received by a component are of the expected types:
NotFound.propTypes = {
location: PropTypes.shape({
pathname: PropTypes.string,
}),
};We can add a propTypes property to any component and list each of the properties within the props object and their types. The code that does this validation will only be included in the development version of the app, it will be completely stripped out in the production version.
It doesn't really matter whether the props were supplied by a component such as React Router as in this case, or by a component of ours. React will always warn about properties within props that are not declared or are of the wrong type. There is no need to declare all the properties, just the ones we use. React Router provides plenty of information, we only declare those we use.
import React, { PropTypes } from 'react';
import Errors from '_components/errors';
import Loading from '_components/loading';
import Menu from '_components/menu';
const App = ({ children }) => (
<div className="app">
<Loading />
<Errors />
<Menu
menuItems={{
projects: 'Projects',
}}
/>
{children}
</div>
);
App.propTypes = {
children: PropTypes.node,
};
export default App;React component may include in their JSX code other React Components besides plain HTML. React expects the tags representing other components to have their names starting with uppercase while plain HTML tags should always be lowercase. React Components can have attributes just like HTML elements can. The Menu component receives a menuItems attribute:
<Menu
menuItems={{
projects: 'Projects',
}}
/>Though we use an HTML-like style to define attributes, in JSX, the values are not restricted to plain strings. In this case, menuItems receives a JavaScript object. There is no need to serialize it into a JSON string as it might happen with a data-xxx attribute in HTML. That is also the reason for the double curly brackets {{ }}, the outer set of brackets is to switch from JSX mode into plain JavaScript and the inner set are those of the object literal.
In the App component we are importing the Loading, Errors and Menu components from the _components virtual location and using them just as we would use any other HTML element.
We are using the children property which is also provided by React Router. children is validated as of type React.PropTypes.node which represents any kind of React component.
Routes in the browser behave differently than routes in the server. In the server, the first route that matches the requested path gets called and it sends via res.send the information back to the client. There is no nesting, the first match does it all. We are not talking about middleware here, which can do some processing and pass on the request for others to deal with. On the server side, the first res.send or its equivalents, ends the operation. This is because the response to an HTTP request is a simple stream.
Routes in the client are meant to affect a two-dimensional screen where each part of the route might influence a particular section of it. For example, most web pages will have a standard look, starting with an enclosing frame with the basic color scheme, perhaps the company logo, a copyright sign and so on. Within that frame there might be other standard sections such as a header or footer, perhaps a menu or tabbed interface and finally, there will be one or more sections that are totally dependent on the route. For example, a mail-client program will have a main section that contains the list of folders for the /, a list of messages in the inbox for /inbox or a particular message for /inbox/de305d54-75b4-431b-adb2-eb6b9e546014. Each responds to a fragment of the full URL and they all combine to build the full screen.
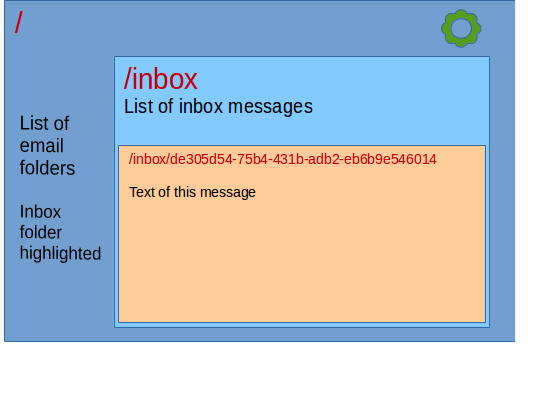
The image above shows how the different parts of the URL bring up different sections on the screen layout for such application, with each section dealing with a little bit more of the URL and enclosing the more specific section. That is why client-side routes are hierarchical and why one component may have a variable children that might be assigned by the Router. It is like a place-holder for whatever subordinated content there might be.
# Connected Stateless Component
Stateless components, as it name implies, do not contain any state. However, they can access state information held by others, such as data from the Redux store. The Loading component () is one such.
export const LoadingComponent = ({ loading }) => (
<div
className={classNames(
'loading',
styles.loading,
{ hide: !loading }
)}
>loading</div>
);As any stateless component, it is a simple function which receives some properties. Since we are interested in props.loading we use ES6 Object Destructuring to get just loading extracted from props, plus shorthand property names. This is not React or JSX, it is plain ES6.
The Loading component has a simple div containing a text message when anything is loading from a remote source. It has a className attribute. React accepts almost all HTML attributes, but has a few exceptions. The class attribute would mess up JSX parsing because class is a reserved word in JavaScript and so is for. That is why in React, we should use className instead of class and htmlFor instead of for.
We are composing the className attribute via the classNames utility, which allows us to easily concatenate various class names from different sources, some of them conditionally. That is what we are doing with the { hide: !loading } part. classNames will add the name of the property hide to the list of class names depending on the truthiness of its value which, in this case is the inverse of the boolean value of props.loading.
The loading class name is just a common practice. When inspecting the HTML it is an easy way to identify which element is which, otherwise, all of the <div>s really look alike. With so much of the HTML produced dynamically through React Components, it is difficult to associate the resulting HTML with the code we have written. The React Developer Tools do this for us, but they only work in Chrome and Firefox and not at all with the static HTML produced in the server via isomorphism. It is a debugging aid not required in production and might be omitted.
The hide class name comes from Bootstrap.
The styles.loading class names comes from the following include:
import styles from './loading.css';Importing CSS files is a feature provided by WebPack's CSS-loader. The loading.css file () is a normal CSS file. WebPack can also pack CSS and load them on the client. An interesting feature of such loading is that the CSS-loader generates unique class names for the included classes, excluding any possibility of name clashes. The CSS-loader also understands CSS-modules and optionally translates identifiers invalid in JavaScript such as those with dashes: my-class-name to JS-compatible camel-case: myClassName
In this example, styles.loading might contain _3ZmMd6h2aKqY_GEJqAEiQN and the client.css bundle generated by WebPack will define the style for that unique identifier.
LoadingComponent.propTypes = {
loading: PropTypes.bool,
};We declare the type of the loading property within props to be a boolean. All these type-checking code disappears automatically when building the production version so there is not cost in the final product.
We didn't call our component Loading, as the file name suggests, or the way we imported it in app.jsx () but used LoadingComponent instead. That is because our default export is not LoadingComponent but a wrapped version of it.
# React-Redux
export const mapStateToProps = state => ({
loading: !!state.requests.pending,
});
export default connect(
mapStateToProps
)(LoadingComponent);We might have several requests pending at any one time from various sources. It is not practical for all those possible sources to know how to notify the Loading component when they start a request or receive a reply. We could use some sort of global event system, but that would be messy. Instead, we use the Redux Store to do so. Also, we cannot use a simple boolean flag, we need instead to count pending requests. When there are any pending requests it means the loading status is true, when it comes down to zero, loading is false.
mapStateToProps is a customary name for a function that receives the state of the Redux Store and returns an object that maps the values currently in the store into the name of the props that the React component will receive.
The connect function from react-redux merges whichever props the component is already receiving from its parent with those provided by mapStateToProps and calls LoadingComponent whenever the store changes.
connect returns what is called a High-order Component or HoC. It is a true React Component which has the wrapped component as its only child. It is invisible to the user, it adds nothing to whatever its child renders. As a regular React component, it receives properties from its parent, it then merges them with those coming from the store thanks to mapStateToProps and calls our stateless LoadingComponent. The latter does not need to care about Redux or its store, it just receives a plain props object with all it needs to know to do its simple duty. The HoC also subscribes to the store to receive notifications of any changes so that it knows when to redraw the wrapped component.
We export the wrapped component as the default because, for all any other component might ever care, the wrapped component is just as good as the stateless LoadingComponent. No other component should really care whether a component is wrapped by a HoC or not.
We diverge from the example given in the Redux documentation in that we don't separate presentational from container components into different folders. Container components are those wrapped with
connect. The author clearly states in the FAQ that there is no preferred structure for a project using Redux and lists several options. We see no benefit in separating wrapped components from simple ones. As we will see later, there can be many HoCs and we cannot allow those HoCs to define the structure of our project.
Though we export our wrapped component as the default, we still export
LoadingComponentandmapStateToPropsas named exports. The React application itself would only care for the default export, however, for the purpose of unit testing, it is good to have the other units exposed to be able to test them individually. We don't really need to test the full connected component. If the plain, un-connected component works andmapStateToPropsworks, it is safe to assumeconnectwill do its work.
# Router HoC
export default withRouter(MenuComponent);In menu.jsx () our default export is also a wrapped component. In this case, we use the withRouter HoC from React-Router:
import { Link, withRouter } from 'react-router';The withRouter wrapper from React Router adds a router property to the props argument of the wrapped component. We use the router.isActive method to know which tab in the menu to highlight as active.
export const MenuComponent = ({ router, menuItems }) => (
<ul className={styles.tabs}>
{
map(
menuItems,
(caption, path) => (
router.isActive(path)
? (
<li key={path} className={styles.active}>
<a>{caption}</a>
</li>
)
: (<li key={path}><Link to={path}>{caption}</Link></li>)
)
)
}
</ul>
);MenuComponent produces a tabbed navigation bar. It accepts the menuItems object which contains a series of unique paths as property names and the caption for the corresponding tab.
menuItems={{
projects: 'Projects',
}}It creates an un-ordered list of list items which, thanks to Bootstrap Tabs. We are not using Bootstrap prescribed class names in our code. We could use pills instead of tabs since the actual style definitions are in the imported menu.css file () which uses CSS-modules to compose them out of the Bootstrap styles. If we change the composition of styles from nav-tabs to nav-pills or to whichever classes another library might use, we change the look of the menu.
Since menuItems is not an array but an object, we resort to Lodash mapfunction which works in both arrays and objects. Lodash is a large library and loading the whole of it for just one or two functions would be too expensive. Many such libraries have been modularized. Instead of importing everything from the library and using parts of it, we can request only what we will use. So, instead of doing import _ from 'lodash'; and then using the _.map() function, we can import just the map function:
import map from 'lodash/map';When using the map function, instead of doing menuItems.map( ... ) as we would do if it was an array, we do map(menuItems, ... ). The callback receives the property values and property names, which we call caption and path. Depending on whether the path is active, via router.isActive(path) we display either an inert link (it has no href) with the styles.active style. The <a> element is just because Bootstrap (or any other styling library) expects one otherwise it won't look right.
For the rest of the links, we use a <Link> component which we also import from React Router. This component produces an actual <a> so Bootstrap can be kept happy, but ensures that React Router will catch that request for navigation and process it itself.
Note that we are returning an array of <li> elements. The map function returns an array of whatever the callbacks return and the callback is a fat arrow function which implicitly returns the value of the expression in it. That expression is a ternary conditional expression retuning either kind of link.
Whenever we have an array of items such as the <li> elements in this component, it is important that we assign each of them a key pseudo-attribute containing a unique id within the array (the ids might and will probably repeat over and over in an application, they just have to be unique within each array). React uses this pseudo-attribute to identify each item even as its contents or attributes change, otherwise, React wouldn't be able to know if an item with a different content is meant to be a different element or the same element with its contents changed. It becomes particularly useful when elements are inserted or deleted because it allows it to actually insert or delete just that element from the DOM instead of re-render them all from the mismatched element on. We must ensure the key is a permanent and lasting id for the element, not just a sequentially assigned integer which changes in each render, that would be as bad as not providing any key at all.
As expected, the types of the props are declared both as objects:
MenuComponent.propTypes = {
router: PropTypes.object,
menuItems: PropTypes.object,
};# Dispatching Actions
We have seen how we can reflect the state of the store in a connected component but, so far, we haven't seen how we can affect the store in response to an action by the user.
export const ErrorsComponent = ({ errors, onCloseErrors }) => {
const closeErrorsHandler = ev => isPlainClick(ev) && onCloseErrors();
return (
<div
className={classNames(
'errors',
styles.errorsList,
{ hide: !errors.length }
)}
>
<button onClick={closeErrorsHandler} className={styles.closeButton} />
{
errors.map(
process.env.NODE_ENV === 'production'
? e => e.message
: e => JSON.stringify(e, null, 2)
).join('\n')
}
</div>
);
};ErrorsComponent receives an array with a list of errors and it simply displays it after chaining them together via{errors.join('\n')} in an overlaid box only when the length of the list is not zero. The list of errors is more or less verbose depending on the value of process.env.NODE_ENV, if it equals production it simply shows the plain message, otherwise it assumes it is a development version and shows more details. React itself checks process.env.NODE_ENV to conditionally enable plenty of diagnostics such as checking the PropTypes, we are simply using the same mechanism.
The box contains a button to let the user acknowledge the error and clear the error list. Upon clicking on that button, closeErrorsHandler is called which uses the ev event object to check whether the click was a plain left-button click with no modifier keys (shift, control and such)
export default (ev) => {
if (ev.button || ev.shiftKey || ev.altKey || ev.metaKey || ev.ctrlKey) return false;
ev.preventDefault();
return true;
};isPlainClick checks the ev object for the corresponding properties and returns false if any is non-zero or true. If the click is a plain one, it prevents the default action associated to the event and returns true.
In that case, the component calls onCloseErrors which it received as a property (destructured from the props object). We used the on prefix to mark it as an event listener as with DOM event listeners. Just like errors is produced via mapStateToProps from the Redux store, so onCloseErrors is produced by mapDispatchToProps:
export const mapDispatchToProps = dispatch => ({
onCloseErrors: () => dispatch(clearHttpErrors()),
});mapDispatchToProps is a function that receives a reference to the store.dispatch method. This is the method through which we notify the store that something has happened. When using Redux, we only maintain one store so when we dispatch something, it can only go to one place.
dispatch dispatches actions, which usually are objects containing all of the information needed for the action to be performed. Those objects may be complex to assemble so, to make it easier, we use action creators which assemble them for us. We will learn more about actions and action creators in a moment, for the time being it is enough for us to know that clearHttpErrors is one such action creator, thus, we are dispatching the action that the clearHttpErrors action creator has assembled for us.
Just as mapStateToProps, mapDispatchToProps returns an object that will be merged along the rest of the props received from the parent. Both are exported by name for testing purposes and the types of both sets of properties have to be declared:
ErrorsComponent.propTypes = {
errors: PropTypes.array,
onCloseErrors: PropTypes.func,
};Though it was not used in this case, mapDispatchToProps also receives a reference to the same props the component would receive, to help it assemble the actions. mapDispatchToProps (not the functions it returns) will be called again whenever the props change so that the returned functions are bound to the most recent properties.
export default connect(
mapStateToProps,
mapDispatchToProps
)(ErrorsComponent);mapDispatchToProps is used as a second argument for the connect method that wraps our simple stateless component with the HoC.
We have split the functionality of dispatching the action into two functions, closeErrorsHandler and onCloseErrors and it might seem redundant because it could have all be done in just one place, checking the event with isPlainClick and then dispatching the action all in onCloseErrors and completely drop closeErrorsHandler. We prefer to have the UI-related functionality within the component itself. Checking to see if the button was left-clicked assumes you expect a click, but some other interface design might use some other kind of user interaction. Since the component determines the way the user can respond, it is the component that should be responsible to verify it.
At a later point, the range of interactions with a particular screen element might grow, we might have it behave in one way when left-clicked and another when right-clicked. Would it make sense to the left vs. right click verification in the mapDispatchToProps? Hardly.
Note also that the ev event object never leaves the component itself. The component deals with the DOM and the DOM should never spill out of the component to the rest of the application. All our custom pseudo-events should be application-oriented, not DOM-related. If they were to have any arguments passed, they should be related to the application, not to the DOM. Even just passing on the ev object to our custom event might cause an unexpected dependency in the future as someone might use some property in it for whatever purpose, thus prevent the user interaction from changing from clicking to blinking while staring at it, or whatever future user interfaces might offer.
# Stateful Components
So far we have seen stateless components which are simple functions that returns a visual representation of a section of a page, based on a series of properties it receives as its arguments. If the properties change, the representation changes, if they don't, it doesn't. Stateless components are very predictable. They hold no internal state that might make them respond in different ways to the same set of properties.
In contrast to that, stateful components do hold state. To do so, first of all, they are declared as JavaScript classes so that their instances can have a this context. They have two main properties, both objects containing several keyed values:
this.propsare the very same properties stateless components have. They come from components higher up in the hierarchy. A component should never change the properties it receives.this.stateholds the internal state of the component. It is created within the component and managed by it.
The classic example of a stateful component is a form. When initially called the component will receive, amongst other possible properties, the values of the fields to be edited in the form. These properties do not change over the lifecycle of this particular instance of the form component.
As the fields in the form are filled, the visual representation of it will change. Input fields will be filled in or edited. As fields are validated, error messages might show. Calendars might pop up to help in filling in dates. Action buttons might become enabled as the data changes. During all of this process, this.props never changes while this.state does so continuously.
Stateful components are created by extending the React.Component class. They can still be created by calling React.createClass, as most documentation about React shows and both mechanisms are very much alike, however, since we are using ES6, we will stick with the class instead of the factory way.
export class EditProjectComponent extends Component {
constructor(props) {
super(props);
this.state = pick(props, 'name', 'descr');
bindHandlers(this);
}We declare the EditProjectComponent as a class that extends React.Component (we extracted the Component export from the React library on importing it ()). Its constructor receives the props just as the stateless components did. After calling the constructor of the super-class it sets the initial state. Then it goes to bind its own action handlers, something we will see later after dealing with the state.
# State
The state should only hold information that is meant to be changed during the lifetime of this component. The props might contain lots of other information, such as onXxxx custom event handlers, strings for headings and even routing information. We should avoid cluttering state with all this extra information, we should just pick from props that which will change and we do so by using Lodash pick function, extracting just the name and descr properties, which we intend to edit. We might also initialize other state properties by merging them with the ones picked from the props.
We should never set state directly, except in the constructor, this is the only time we will see this.state on the left hand side of the assignment operator. We can read directly from this.state but never write into it, except in the constructor. Later changes to state should be done via the setState method, as we will see later. setState not only changes state but also signals React that something has changed and so the component might need a re-render. setState queues a re-render, which will not happen immediately and, in certain circumstances, it might not happen at all or it might be subsumed within a wider redraw. React takes care of optimizing this and we might help by declaring the shouldComponentUpdate method. As always, it is never a good idea to start by over-optimizing so, we will leave shouldComponentUpdate alone. Should a performance test show a particularly slow component, then we can use shouldComponentUpdate.
state will contain an object with multiple properties. setState expects an object with new values for just the properties that need changing. It will merge (never replace) the object it receives with the object it has already stored.
state will usually contain a relatively flat object, just a set of key-value pairs. A deeply nested hierarchy of objects is usually a sign that the component is dealing with too many things and might need breaking up into several, smaller, simple components. Besides, it is the Redux Store the place to deal with the bulk of data.
# Event handlers
onChangeHandler(ev) {
const target = ev.target;
this.setState({ [target.name]: target.value });
}
onSubmitHandler(ev) {
if (isPlainClick(ev)) this.props.onSubmit(this.state);
}
onCancelHandler(ev) {
if (isPlainClick(ev)) this.props.onCancelEdit();
}We identify our internal event handlers with the onXxxxxHandler pattern. Some of them, onSubmitHandler and onCancelHandler, after checking that the click was a plain one, that is, left button and no shift, alt or ctrl keys, it calls the external event handler received along the rest of the props. Neither passes on the ev event object out of the component, as we have already discussed at the end of the previous chapter. If we pass any arguments out of the component, they should be application-related, like in onSubmitHandler which passes this.state that should contain an object with only name and descr properties, which is all the outside world should care about from this component. Should the state contain anything else, as it often happens, then we should pick whatever is relevant.
To make sure onSubmitHandler can pass the true state of the form at any time, we should keep state updated at all times. That is what onChangeHandler does. We attach onChangeHandler to every input field in the form. We name the input fields by the name of the property they affect so, a single handler can deal with all of them. We get a reference to the input field from ev.target and then we use the name and value of that input field to set its state.
this.setState({ [target.name]: target.value });Two important differences in between React's virtual DOM and the real DOM:
- The
onChangeevent is fired whenever a field is changed, not just when the focus leaves the field. Each and every keystroke or paste into a field changes it thus listening to theonChangeevent provides a continuously updated image of the field. - All input elements have a
valueproperty, even<textarea>and<select>and they provide what you would really expect. This standardizes the way to access their value regardless of their type.
We could have attached a separate handler for changes in each of the two fields but thanks to the above item, we can manage with only one.
We have to be careful with field validation. When using real DOM, we might run a full-field validation when the user moves the focus out of a field by listening to onChange. This is not the case with React when onChange fires while the field is still being edited.
We will attach all the handlers above to the events in the buttons and input fields in the form. The problem with doing so is that event handlers are called in the context of the element that fires it, that is, the this for the handler is the DOM element, which has no this.setState method. That is why the handlers must be bound to the this of the instance of EditProjectComponent.
There are two ways to do it. When creating the element we might do:
onChange={this.onChangeHandler.bind(this)}
This is not a good idea because the component might be re-rendered many times, as a matter of fact, it will be re-rendered on each and every keystroke. Each call to bind leaves behind a bit of memory and, even though they are deleted as anew bound copy is created, we would be leaving behind a lot of trash for the garbage collector to dispose of. Instead, we bind them all just once when the instance of EditProjectComponent is created with the bindHandlers function:
const rxHandler = /^on[A-Z]\w*Handler$/;
export default (obj, regXp = rxHandler) => {
Object.getOwnPropertyNames(Object.getPrototypeOf(obj)).forEach(prop => {
if (typeof obj[prop] === 'function' && regXp.test(prop)) {
Object.defineProperty(obj, prop, {
value: obj[prop].bind(obj),
configurable: true,
writable: true,
});
}
});
};We have already called it in the constructor (). bindHandlers looks within an object for properties that are functions and follow the naming pattern onXxxxxHandler and binds them to that object. The naming pattern can easily be changed by passing a second argument containing a regular expression. It doesn't work on inherited methods which, presumably, should have been bound in their own constructors.
# The render method
Finally we reach the render method () which is very much alike our earlier stateless components, the difference being that render receives no arguments, this, it has to read the values from either this.props or this.state. For example, the name field:
<div className={styles.formGroup}>
<label htmlFor="name">Name</label>
<input
className={styles.formControl}
name="name"
onChange={this.onChangeHandler}
value={this.state.name}
/>
</div>Its value is set from this.state.name and its onChange event listener is set to the already bound method this.onChangeHandler.
<button
className={styles.okButton}
disabled={this.state.name.length === 0}
onClick={this.onSubmitHandler}
>Ok</button>We can easily enable/disable the Ok button by checking the length of this.submit.name, which is the only mandatory field. Since the state is constantly updated on each and every keystroke by the onChange listener, the enabled state is updated continuously. That is not completely true, React's internal representation of the DOM will be updated but, if there is no change, the actual DOM attribute will not be changed.
Note that we are not using the <form> onSubmit handler, though the handler is called onSubmitHandler, we are listening to the click on a simple button. As a matter of fact, there is no actual <form> element in the form, just a collection of fields, labels and buttons nicely formatted with the class names in the styles object.
# The exposed event handlers
As with stateless components, we generate the external event handlers with mapDispatchToProps:
export const mapDispatchToProps = (dispatch, { params: { pid } }) => ({
onSubmit: ({ name, descr }) => {
if (pid) {
return dispatch(updateProject(pid, name, descr))
.then(() => dispatch(push(`/projects/${pid}`)));
}
return dispatch(addProject(name, descr))
.then(response => dispatch(push(`/projects/${response.payload.pid}`)));
},
onCancelEdit: () => {
dispatch(replace(
pid
? `/projects/${pid}`
: '/projects'
));
},
});The same component serves both to edit a project as well as for adding a new one, the difference is that when editing an existing project, the project already has a pid while new ones don't. In both onSubmit and onCancelEdit we first branch off to different dispatches, an updateProject if there is pid or addProject for a new project. Note also how we chain further actions after the update or addition of the project. By adding a .then() to the first dispatch, we are navigating away from the editor. If it is an existing project, we already have the pid but, if it is a new project, we find out the pid it got assigned from the reply to the addProject action.
We have not defined a mapStateToProps function for this component because we are using the very same one from project.jsx by importing it. That is one more reason to always export those functions, besides doing unit-testing on them, we can reuse them in related components.
For the time being, we will ignore initialDispatch and initialDispatcher which help ensure that the component has its initial data set to display. We will look at them in depth when we deal with isomorphism.
# (Un)controlled components
There is a discussion in the React documentation about controlled and uncontrolled components. The one we've seen is a controlled component, so called because React is always in control, by listening to its changes and redrawing it all the time. Uncontrolled ones are simply left to run free, no onChange listener, no setting of its value from this.state. An uncontrolled component might well be rendered by a stateless component, as all its state actually resides in the DOM itself. However, by having no control over the form, we would be unable to do sophisticated things with it via React. In an uncontrolled form, setting the enabled state of the Ok button or doing on-the-fly validation would require some extra scripting or using JQuery or similar tools, which would be a pity.
Another issue with uncontrolled components is that the state is stored in the DOM and thus be lost if React re-renders the component. This should not happen as React always tries to reduce the changes to the DOM and there is no reason why a change anywhere else in the page should force a refresh in an unrelated component. If an uncontrolled component gets its fields wiped out, it usually means there is a problem elsewhere.
If none of the above is an issue, there is something we do need to take care in uncontrolled components. In general, we should not set the value of an uncontrolled component. React provides us with an extra pseudo-attribute called defaultValue. This is the value that the field will be set to when it is not already set, that is, when it is initialized. This is one more way in which React can preserve what the users has typed in an input field if the component gets refreshed. The defaultValue would be used only when the field is rendered the first time.
# Routing
We are using React-Router for our client-side routing, coupled with react-router-redux to navigate by dispatching regular Redux actions and keep the store in sync with the location information.
Instead of having a single file holding routing information for the whole application, we have spread the responsibility to each of its parts, in this example, the only one we have, Projects.
import React from 'react';
import { Route } from 'react-router';
import ProjectList from './projectList';
import EditProject from './editProject';
import Project from './project';
export default path => (
<Route path={path} component={ProjectList}>
<Route path="newProject" component={EditProject} />
<Route path="editProject/:pid" component={EditProject} />
<Route path=":pid" component={Project} />
</Route>
);React routes can also be written using JSX because each Route is a React Component. For each route the router matches the path of the URL with the component that then gets called. Just like in server-side Express routes, the colon precedes variable parts that will be turned into named parameters, in this case :pid. The component will receive this parameter as one more property as props.params.pid:
export const mapStateToProps = (state, props) => {
const pid = props.params.pid;Routes can be nested. The outermost route receives its path from the parent, so as to consolidate the assignment of paths in one place, thus avoiding possible clashes. Assuming the parent passes projects for path, all this section of our app would be contained under the /projects path, for example /projects, /projects/newProject, /projects/editProject/25 or /projects/25. Note that, unlike Express routes, all components that match part of a route are called, not just the first match. Thus, for /projects/25 both the ProjectList and the Project components will be called with Project being embedded wherever the {children} placeholder () within ProjectList says.
The same EditProject serves both to add a new project as well as for editing an existing one, the difference being that when editing, the pid parameter will not be null.
# Routing file structure
React-Router doesn't force any particular file structure as to where and how its routes are declared. Many applications have just one big master routing file. We prefer to delegate routing to each of the parts of the application.
The set of routes above serves only the Projects part of what could be a more complex application. Note that the import paths to all the components point to files in the very same folder. It is all self-contained. The set of routes is the default export in index.jsx, which is the default file name/extension for file imports. Thus, when higher up in the hierarchy we write:
import projects from './projects';we are actually importing the routing information to branch off to each of our components depending on the URL. As a matter of fact, the whole of the parent routing file has a very similar structure:
import React from 'react';
import { Route } from 'react-router';
import App from './app';
import NotFound from './notFound';
import projects from './projects';
export default path => (
<Route path={path} component={App}>
{projects('projects')}
<Route path="*" component={NotFound} />
</Route>
);All file import paths point to files (./app, ./notFound) or folders (./projects) in the very same folder it resides. The routes are the default export and the file is the default filename with the default extension.
The path for the root component in this file is received as an argument from the parent. In our case, that root path is / but the whole application could easily be moved elsewhere. It calls the App component, which is the overall frame that encloses the whole application. The * path, which is a wild-card, catches any path that doesn't match any route, thus it shows the NotFound component.
Nested under the route for /, we have {projects('projects')} which brings the routes for the Projects part of the application and tells it which path it should respond to. Should there be other parts, as a normal application would certainly have, they would be added here as well, each receiving its own unique root path.
Going further up we get to the entry point for the client-side application. We will come back to this file later on, as there are a few other things we need to look at before dealing with the rest of it. As for the routing part, this is what we care about:
const dest = document.getElementById('contents');
export default render((
<Provider store={store}>
<Router history={history}>
{components('/')}
</Router>
</Provider>
), dest);To get our React app going, we call the render function imported from react-dom () and tell it which React component to render and the DOM element render it in. Here we are using two React Components that are not visible:
Providercomes from React-Redux and it is the means it uses to make thestoreavailable to all the components in the application. TheconnectHoC we have used () to make our components aware of the store takes it from Provider.Router(note the spelling,Router, notRoute) is the one actually managing the routes configured below. It also provides thewithRouterHoC. It receives a reference to thehistoryto use.
Finally, the {components('/')} embeds the routes from our application right at the root URL path.
Client-side navigation can be done via window.history, however, different implementations on various browsers makes it impractical to handle it directly. The history package provides a uniform mechanism across all browsers. React-Router adds a further layer on it an offers three varieties. We will use the recommended one, browserHistory:
import { Router, browserHistory } from 'react-router';
import { syncHistoryWithStore } from 'react-router-redux';We add a further layer upon it through syncHistoryWithStore which enables the state of the browser history to be reflected in the store:
const history = syncHistoryWithStore(browserHistory, store);It is that store-synched browserHistory which we tell <Router> to use.
# Actions
In Redux parlance, actions are signals sent to the store to let it know that something has happened so the store can have its state adjusted.
It might be a good time for some basic definitions.
- Store is where all the data handled by Redux is kept and by extension everything related to its operation.
- State is a snapshot of the data in the store.
- Action is an object that contains enough information for the store to act on it and possibly change its state
- Action Type is the value of the
typeproperty of the action which serves to identify each kind of action. - Action Creator is a helper function that assembles an action.
- Dispatch is when an action gets queued with the store so it gets processed.
- Reducer is a function that actually changes the state of the store based on the information received in the action.
Except for the reducer we have already mentioned the others. We will see reducers in the next chapter.
The only action creator we have seen so far has been clearHttpErrors:
export function clearHttpErrors() {
return { type: CLEAR_HTTP_ERRORS };
}Since it has no arguments, it always returns the very same object, which is the actual action that would eventually be dispatched. An action is an object with, at the very least, a type property, which is usually a descriptive string:
export function clearHttpErrors() {
return { type: CLEAR_HTTP_ERRORS };
}To ensure the uniqueness of the strings, we make them out of several parts separated by slashes, the first part being the part of the store they deal with which, in this case, is reflected in the folder containing its source code.
Though the new Symbol object could be used to create unique action types, it is not a good idea because they are hard to visualize in the debugger, after all, the only thing the developer could visualize in the debugger is the description. Thus, though two symbols would always be different, their descriptions might not and that would confuse anyone tracing a bug. For example:
Symbol('hello world') === Symbol('hello world')
// returns false
Symbol('hello world').toString() === Symbol('hello world').toString()
// returns true.
The toString() value is what the debugger would show thus, we would still need to create unique descriptions. Symbols don't actually require descriptions, but that would still be worse because then they would all be anonymous.
Most importantly though is that Symbols cannot be serialized. JSON will ignore them just as it does with functions. In any application connecting several clients, such as games or chat, actions must be transmitted to remote systems and Symbols simply don't get through.
JSON.stringify({type: Symbol('hello world')})
// returns {}
# Asynchronous actions
Regular actions are good for situations when you have all the information already available. In the action we create via our clearHttpErrors action creator, there is no extra information just the action type. Sometimes, to fulfill an action, we might need more information, for example, a response from a data server. This is complicated to handle via plain, basic Redux but we may add some middleware to help us.
Redux-Thunk can be added to a Redux store so it processes the actions before they get acted upon. When Redux-Thunk receives an action, if it is a function, it will call it, otherwise it lets it pass through. Redux-Thunk provides two arguments, the dispatch and getState methods of the store. Usually, only dispatch is used as any other information required can be provided by the code calling the action creator.
The lifecyle of a typical async action creator has a few basic stages:
- dispatch a plain action to signal that the action has been initiated
- start the async requests
- on a successful reply, dispatch a plain action with the information just received
- if the request fails, dispatch a plain action with the error information
export default (type, asyncRequest, payload = {}) =>
dispatch => {
dispatch({
type,
payload,
meta: { asyncAction: REQUEST_SENT },
});
return asyncRequest.then(We have created a utility function asyncActionCreator that helps us with this. It receives an action type, the actual async request, which can be anything that returns a Promise and a payload which is an object containing the information related to the request.
asyncActionCreator returns a function, which allows Redux-Thunk to identify it as an asynchronous action. It then calls it passing a reference to dispatch as an argument. asyncActionCreator first calls dispatch to indicate that the async action has been initiated. For all its actions, it uses the Flux Standard Action (FSA) format, which provides a predictable and flexible format to pass information. Redux itself does not require any particular format, it only cares about the type property, but anything that makes matters more predictable is good.
FSA expects an action to have only four properties with type being the only mandatory:
type: mandatory, as per Redux rules.payload: an object with all the information related to the action.error: a Boolean, usually only present if it is true, it indicates a failed request. If so,payloadshould contain an error object.meta: A place for whatever extra information might be required.
In our initial action, we are using the type and payload received as arguments and we are adding in the meta an object with the asyncAction property set to REQUEST_SENT, a sort of sub-action type that signals that this is the initiation of the action signaled by the actual type. Thus, for an action type of ADD_PROJECT we will have an ADD_PROJECT/REQUEST_SENT and then an ADD_PROJECT/REPLY_RECEIVED or, if anything fails an ADD_PROJECT/FAILURE_RECEIVED.
Since the asyncRequest argument is a Promise, we attach to the then part and return that, which is still a Promise.
response => dispatch({
type,
payload: Object.assign(response, payload),
meta: { asyncAction: REPLY_RECEIVED },
}),For the resolve part of the then we respond by dispatching an action with the same action type but with a REPLY_RECEIVED sub-action type. For the payload, we merge the data received in the response with whatever came in the payload argument. Even if the reply is an array, as it frequently is, Object.assign will work and return an Array with the extra properties from payload added.
error => {
const err = {
status: error.status,
statusText: error.statusText,
message: error.toString(),
actionType: type,
originalPayload: payload,
};
return dispatch({
type,
payload: err,
error: true,
meta: { asyncAction: FAILURE_RECEIVED },
});
}
);For the reject part of the then we assemble an err object which is a plain object literal, not an instance of the Error class. This is because it is not a good idea to store class instances in the store. The reason is similar to why we prefer not to use Symbols for action types, neither is serializable. In isomorphic applications, it is not enough to send the rendered HTML from the server to the client, it is also important to send the data that produced it and to do that, we have to serialize the store. Dates already pose a problem on serialization, we can do without further class instances.
As per FSA, we set the error property and send the error object as the payload. We include both the actionType and the originalPayload as part of the error object, just in case any component might need it.
We have opted to use the same action type for all three possible messages for each action. We then discriminate amongst them via the asyncAction property in meta. This is just a matter of choice and neither Redux nor FSA forces us one way or another.
The use of a consistent sub-action for async actions allows us to easily count outstanding async requests and thus show the Loading component. On each REQUEST_SENT sub-action the pending count goes up, regardless of the action type. On each REPLY_RECEIVED or FAILURE_RECEIVED, the pending count goes down. Additionally, on each FAILURE_RECEIVED, the payload, which contains the error object, is saved for later use. We will see how this is done in a later chapter.
# Using asyncActionCreator
As with all actions, we first define the action types:
const NAME = 'projects/';
export const ALL_PROJECTS = `${NAME} Get all projects`;
export const PROJECT_BY_ID = `${NAME} Get Project by id`;
export const ADD_PROJECT = `${NAME} Add Project`;
export const UPDATE_PROJECT = `${NAME} Update Project`;
export const DELETE_PROJECT = `${NAME} Delete Project`;To perform HTTP REST requests, we use the new fetch global method. Since not all browsers or NodeJS versions support it, we use suitable polyfills, which we will look at later on. For the time being, we may assume window.fetch or global.fetch are present, somehow. We use a small utility to provide us with pre-configured instances:
restClient = method => (path, body) => fetch(
`${HOST}:${PORT}${join(REST_API_PATH, base, path)}`,
{
method,
headers: {
Accept: 'application/json',
'Content-Type': 'application/json',
},
credentials: 'include',
body: body && JSON.stringify(body),
}
)
.then(response => (
response.ok
? response
: Promise.reject({
status: response.status,
statusText: response.statusText,
message: `${method}: ${response.url} ${response.status} ${response.statusText}`,
})
))
.then(response => response.json());
}
return (clients[base] = {
create: restClient('post'),
read: restClient('get'),
update: restClient('put'),
delete: restClient('delete'),
});As the last few lines show, this utility returns an object with the basic four CRUD methods, created from restClient. Each of those methods will take a URL and optionally a body and it will return a Promise which, on success (the .then part) will return the data requested or on failure (the .catch part) an error object which might be an actual instance of Error or just an object literal with error information. Since our errors go into the Redux Store and it is not recommended to store non-serializable objects such as an Error instance, for our own custom errors, we don't bother creating ephemeral Error subclasses which we would then have to convert back to plain objects to have them stored.
restClient calls fetch with a full URL made up from our predefined HOST, PORT and REST_API_PATH constants, then the base entry point for this family of APIs, such as projects and then the relative path for this request. In the configuration we set the method from the argument, set the headers to tell we are going to use JSON in both directions, set the credentials so that cookies can be sent and, if there is a body we encode it with JSON. Then, if the response is ok, that is, in the 2xx series, we return the same response to allow the processing to keep going, otherwise, we use Promise.reject to force an failed response.
The same source file contains a part that is meant for use with Electron. We will look at it later.
We use the client object to cache the pre-configured client connection to each of the base entry points.
We also create some handy aliases for the regular HTTP verbs. It is easy to confuse PUT and POST so we create aliases for the 4 CRUD operations.
const api = restAPI('projects');With this utility it is easy to create an instance by just providing the specific entry point for this set of operations.
export function getAllProjects() {
return asyncActionCreator(
ALL_PROJECTS,
api.read('?fields=pid,name,pending')
);
}The getAllProjects action creator needs no extra arguments. It calls asyncActionCreator with the ALL_PROJECTS action type and the result of doing a read (or get) operation on the pre-configured connection.
export function updateProject(pid, name, descr) {
return asyncActionCreator(
UPDATE_PROJECT,
api.update(pid, { name, descr }),
{ pid, name, descr }
);
}Other action creators are a little bit more complex because they need to provide more information in the URL, in this case the pid and tid and also extra information that goes in the body of the HTTP request, name and descr. We use descr instead of the customary desc for description because DESC is a reserved word in SQL and many other query languages so using desc as a column name causes lots of trouble. While for the REST API we need to discriminate in between id values that go in the URL and plain data that goes in the body, for the payload argument, we simply pass on all the received arguments in an object. When assembling the payload, we are using the shorthand property names feature of ES6.
Note that in all cases we return the Promise returned by asyncActionCreator which is none other than that the one created initially by the api.read or api.update or whatever asyncAction we initially passed to asyncActionCreator. The dispatch method of Redux always returns the action it receives and if we have React-Thunk to process asynchronous actions, it will return whatever Promise it returns. This allows further chaining, for example:
export const mapDispatchToProps = dispatch => ({
onEditClick: ({ pid }) => dispatch(push(`/projects/editProject/${pid}`)),
onDeleteClick: ({ pid }) =>
dispatch(deleteProject(pid))
.then(() => dispatch(push('/projects'))),
});The onDeleteClick property that mapDispatchToProps provides to the ProjectComponent first dispatches the request to delete the project by pid, then, it dispatches an action to the router push('/projects') to navigate away from the page showing that project, since it has already been deleted. The push action creator comes from React-Router and it is named so because the browser history is handled like a stack so new locations are pushed into it so that they can be popped when going back.
# Reducers
Actions don't directly change the Store, they are just notifications that an operation is requested. The Store is handled by Reducers. Though there is just one store, there can be any number of reducers, each responsible for handling a particular part of that store. All reducers receive all actions, it is up to each reducer to decide whether it cares about it or not. If it does, it updates the Store.
Now that we reach the final, missing element of the Redux architecture, we can trace the workings of an update of a task.
const onTaskEditHandler = ev => isPlainClick(ev) && onTaskEdit({ pid, tid });The Task component has a couple of buttons associated to each item, one to delete the task, one to edit it. The edit button has the onTaskEditHandler event listener attached. Though it follows the naming pattern that bindHandlers () expects, since Task is a stateless component, there is no this to bind it to but, nevertheless, it never hurts to stick to standard naming practices.
After checking that the button received a plain click, onTaskEditHandler calls onTaskEdit with the pid and tid of the task that needs editing. onTaskEdit is a property of Task, produced by mapDispatchToProps () which simply dispatches an action:
onTaskEdit: ({ tid }) => dispatch(setEditTid(tid)),The setEditTid action creator uses just the tid since they are globally unique identifiers so the pid is not needed to identify the task. setEditTid can either receive the tid of the task to be edited or null or undefined to edit no task.
A Redux store can hold application data, such as the projects and tasks our application deals with, but also status information about, for example, pending HTTP requests or, in this case, miscellaneous information such as which task needs editing, if any. That is why we placed this single status information into a catch all sub-store called simply misc contained in a single index.js file in its folder.
import update from 'react-addons-update';
export const EDIT_TID = 'misc/Set tid of task to be edited';
export function setEditTid(tid) {
return {
type: EDIT_TID,
tid,
};
}
export default (state = { editTid: null }, action) => {
switch (action.type) {
case EDIT_TID:
return update(state, { editTid: { $set: action.tid } });
default:
return state;
}
};We first declare the EDIT_TID action type as a string. As with all action types, to ensure (or at least to try to reach) uniqueness, we prefix the string with the folder it resides in.
We then declare the setEditTid action creator function, which we already used in Task. It simply returns an object with the EDIT_TID action type and the tid. Being such a simple action, we did not bother using the FSA format. We export setEditTid so others can dispatch it.
Finally, we get to the reducer. While a single file may have several action type constants and action creators, which we export by name, a file should only have one reducer, which we make the default export.
The reducer receives two arguments, the action and the current state of the store. The action will always be a simple object. Even if we dispatched a function like we do when using asyncActionCreator (), those functiond will never reach the reducer, they will be handled by middleware earlier on. By the time they reach the reducer, all that is left are plain literal objects.
If the reducer receives no state, it means it has yet to be initialized. We use ES6 default parameter values feature to set state to { editTid: null }. We must remember that this is the initial state of a part of the Store a sub-store, if you wish, other reducers will set their sub-stores. Since this sub-store is named misc, this initialization means that the object {misc: { editTid: null }} will be merged with the objects returned by the other reducers on initialization.
We now have an existing or just initialized state and an action. The reducer then checks the action type and if it is one it cares about, it updates the state of the store. Otherwise, the default in the switch statement simply returns the state as it was received. It is important to always return the state, updated or not, because whatever gets returned will be merged into the store and if we forget to return a valid state, we would just wipe out the sub-store.
It is important to handle the default case because all reducers receive all the actions sent by any part of the application, even if they don't care about it. Reducers don't register themselves to handle specific action types, they all receive them all and each decides what to handle and what to leave alone.
If the action type is EDIT_TID then we update the state, with an expression that seems too complicated. That is because of immutability.
# Immutability
Deciding when to re-render the page is one of the factors that most affects an application performance. Since the page mainly reflects the state of the store, detecting when the state has changed is crucial. Comparing two objects with a plain equals obj1 === obj2 simply says whether the variables obj1 and obj2 point to the same object or different ones. This is called a shallow compare. However, a deep compare might detect that two different objects contain the same information, that is the same structure and the same values, though a shallow compare would rightfully say they are not the same. Doing a deep compare, that is, traverse the whole structure comparing the values for each of the properties would be very expensive.
The solution is to keep the objects in the store immutable, that is, never change the object but make a new copy with each change. This is nothing new, in JavaScript, strings are immutable, a string is never changed, updates on a string return a new string with the change in it. However, a deep copy is just as expensive as a deep compare or possibly more. In normal operation there would be more compares than copies and thus wasting time in doing one deep copy might pay off if it saves on doing several deep compares.
There is a nice way to greatly improve the performance of a copy. In a deeply nested object, we can create anew the parts of the tree that have changed and just do a shallow copy of the branches of the tree that have not changed, that is, copy the reference to the unmodified original branch. In our previous code, if we are going to change the value of the editTid property in the misc branch, we don't need to touch other branches such as projects. We make a new object with a new misc property containing the editTid property and its new value, but we just do a shallow copy Of the projects branch.
The React team has provided us with a tool to do that, the update add-on which takes the current state and returns a new state with the updated parts plus the references to the unchanged parts copied over.
return update(state, { editTid: { $set: action.tid } });update takes the current state and an object that represents just the parts we mean to change. We don't need to enumerate the parts that will remain the same, whatever else state might contain, it will be shallow-copied to the new state. The object in the second argument helps locate the part to be changed and then update provides several commands to tell it what to do. All commands start with the $ sign: $set, $apply, $push, $unshift, $splice and $merge. More than one command can be executed at once over different parts of the state.
Here, we are asking to have the editTid property within the sub-store that misc manages, set to the value of action.tid. We immediately return the new state returned by update to Redux for it to merge it with the other sub-stores.
With this mechanism for updating the state, we can now simply compare the states with a shallow compare (state1 === state2) because, if there were no changes, the references would be the same. We can do that at the root level of the store or at any level below.
Facebook also mentions Immutable-js as an alternative. Using Immutable requires the whole application to be aware of it, all our mapStateToProps as well as all our loops over arrays would need to be changed, thus, for the purpose of this book, we prefer to keep it simple. update works on regular JavaScript objects and arrays. Even if we sometimes use some helper functions from Lodash, we believe the code remains simple enough.
# Connecting components
The single store solves one of the big problems in designing an application with multiple components, how to communicate them. For example, in our task editing example, the effect of clicking a button on the Task component affects the TaskList component because it is the TaskList that decides whether to show the Task or EditTask component:
export const TaskListComponent = ({ pid, tids, editTid }) => (
<div className="task-list">{
tids
? tids.map(tid => (
tid === editTid
? <EditTask key={tid} pid={pid} tid={tid} />
: <Task key={tid} pid={pid} tid={tid} />
))
: `No tasks found for project ${pid}`}
{editTid ? null : <EditTask pid={pid} />}
</div>
);If the list of tasks in a project (the tids array) is not empty, then it will show either the Task or the EditTask component depending on whether the tid of the task equals the value for editTid which, of course, is extracted from the store via mapStateToProps:
export const mapStateToProps = (state, props) => ({
tids: state.projects[props.pid] && state.projects[props.pid].tids,
editTid: state.misc.editTid,
});Note also the use of the key pseudo-attribute when rendering the Task and EditTask components. This ensures that React easily identifies what element has changed and leaves the others alone.
# Other reducers
Reducers are not limited to responding to action.type. In the async actions created via asyncActionCreator we are packing extra information in the meta object within the request. The request reducer responds to that:
export default (state = { pending: 0, errors: [] }, action) => {
switch (action.type) {
case CLEAR_HTTP_ERRORS:
return update(state, { errors: { $set: [] } });
default:
switch (action.meta && action.meta.asyncAction) {
case REQUEST_SENT:
return update(state, { pending: { $apply: x => x + 1 } });
case REPLY_RECEIVED:
return update(
state,
{
pending: { $apply: x => (x > 0 ? x - 1 : 0) },
});
case FAILURE_RECEIVED:
return update(
state,
{
pending: { $apply: x => (x > 0 ? x - 1 : 0) },
errors: { $push: [action.payload] },
});
default:
return state;
}
}
};For any action type beyond CLEAR_HTTP_ERRORS, which sets the errors array to an empty one, the reducer branches off based on action.meta.asyncAction. For each REQUEST_SENT it increments the pending count by using the $apply command, which applies the given function to the current value. For each REPLY_RECEIVED it decrements the pending count, ensuring it doesn't go below zero, just in case there was any mismatch.
For a FAILURE_RECEIVED it also decrements the pending count and it also pushes the error information into the errors array. As mentioned before, update can process two commands at once.
As usual, for any other action, it simply returns the state, unmodified.
More than one reducer can act upon the same action. The request reducer responds to any action type with the correct action.meta.asyncAction information, regardless of what the main recipient of the action might do with it. Most of the time, the main reducer will only respond to the action with action.meta.asyncAction set to REPLY_RECEIVED because until the reply is successfully received, there is nothing to do. For example the reducer for the tasks sub-store:
export default (state = {}, action) => {
if (action.error || (action.meta && action.meta.asyncAction !== REPLY_RECEIVED)) return state;
const payload = action.payload;If a reply came with an error or is not of a REPLY_RECEIVED sub-type, it simply ignores it, returning the state, unmodified, not even bothering with what the action.type might have been.
Some failed actions might require a reducer to do something:
export default (state = {}, action) => {
const payload = action.payload;
if (action.error) {
if (action.type === PROJECT_BY_ID) {
const pid = payload.originalPayload.pid;
return update(state, { $merge: {
[pid]: {
pid,
error: 404,
},
} });
}
return state;
} else if (action.meta && action.meta.asyncAction !== REPLY_RECEIVED) return state;
switch (action.type) {If a client requests a non-existing project, the server would respond with a 404 error. If we did nothing about it, the client might keep asking for that same project. Thus, it might make sense to actually signal that error in the store so that the client does not keep asking for it, over and over again. For other action types, we ignore the error since we don't need to change anything in the projects sub-store, the request sub-store is the one dealing with the error.
We also take care of avoiding unnecessary changes. The actions ALL_PROJECTS and PROJECT_BY_ID might be dispatched almost at the same time if a client navigates directly to an URL such as http://localhost/projects/25, for example, by clicking on a link sent in an email by a colleague. The /projects part would trigger the ALL_PROJECTS and the /25 would trigger the PROJECT_BY_ID almost at once. The replies,however, might arrive in any order. That is why we avoid overwriting information that might already be there due to an out-of-sequence reply:
case ALL_PROJECTS:
return update(state, { $merge: payload.reduce(
(newProjects, project) => (
project.pid in state
? newProjects
: Object.assign(newProjects, { [project.pid]: project })
),
{}
) });The list of projects, as it comes from the server, is an array stored in the payload of the action. To improve access time, it is better to have it indexed. Thus, we loop over the projects in payload using reduce to assemble the NewProjects object. We extract the pid from each project in the array an use it as the key in newProjects. However, if a given pid is already present in state, possibly because the reply to PROJECT_BY_ID arrived first, we don't add it to newProjects. When we call update, we ask it to merge the assembled newProjects with the existing ones. Since we skipped over the existing ones when assembling newProjects, update will make a shallow copy of those. We go through a similar process in tasksReducer ()
The other way around is a little more complex because the reply to PROJECT_BY_ID contains more information than the very basic data that the ALL_PROJECTS listing receives. Thus, if the basic project information exists, the extra information needs to be merged with the existing one.
# Store File Structure
The structure of the files for each of the sub-stores varies according to the complexity, though it follows a few simple principles presented in Ducks
- One folder per sub-store
- The reducer for that sub-store must be the default export
- The action creators must be exported as named exports.
- The action types may be exported as named exports, though we prefer to change that may into a must because it helps with unti testing.
- The action types, being constants, follow the C convention for constants, all uppercase characters with underscores in between words.
- Action types are strings with several parts separated by slashes
/with the first part being the name of the sub-store they are being declared in, usually the folder name. - Each folder must have an
index.jsfile which contains all the above exports, either because- they are defined there, like in
misc() - they are consolidated in it by re-exporting the exports of the files they are defined in, like in
projects:
- they are defined there, like in
export * from './actions';
export { default } from './reducer';# Creating the store.
Now that we have all the reducers in place, we can create our store.
import projects from './projects';
import tasks from './tasks';
import requests from './requests';
import misc from './misc';
const reducers = combineReducers({
projects,
tasks,
requests,
misc,
routing: routerReducer,
});We import the default export from the default index.js file from each of the folders for the sub-stores and then we use Redux combineReducers to collect them all into a single reducer. combineReducers takes an object literal with the name to be given to the sub-store as its property names and the reducers as the property values. Since they usually match, we take advantage of ES6 shorthand property names feature, except for routerReducer whose sub-store we will call routing.
export default (history, initialState) => {
const mw = applyMiddleware(reduxThunk, routerMiddleware(history));
return createStore(
reducers,
initialState,
process.env.NODE_ENV !== 'production' &&
typeof window !== 'undefined' &&
window.devToolsExtension
? compose(mw, window.devToolsExtension())
: mw
);
};Our default export in createStore.js will be our function to create the store instance, which calls Redux own createStore with the combined reducers, an initialState and the middleware to use.
Isomorphic applications running on the client side usually receive the initialState from the server, Redux doesn't really care where it comes from. After loading the given initialState Redux will call each of its reducers with a fake action type. When a reducer is called with an empty state, it should initialize it. We've handled that via ES6 default parameter value:
export default (state = { pending: 0, errors: [] }, action) => {In a regular application or on the server side of an isomorphic application, there is nowhere to get the initialState from so it is important to have those default initializers.
The third argument to Redux createStore is a function called an enhancer. Redux provides one such enhancer, applyMiddleware, which takes a series of middlewares and enhances Redux with them. We use applyMiddleware to load redux-thunk, which handles asynchronous actions, and the routing middleware, which is the one needing to access the history being used.
There are other types of enhancers such as the Redux DevTools which are also available as browser extensions for Chrome and Firefox. If any of them has been installed in the browser, they show up as a function in window.devToolsExtension. So, if we are not in production mode (which presumably means we are in development mode) and there is a global window variable and that window has a devToolsExtension, we combine the middlewares with the development tools, otherwise, we simply use the middlewares only. combine simply calls each of the functions in sequence, which is all the enhancers need.
To make it easy to access the action creators, we can also collect them into one export:
export * from './projects/actions';
export * from './tasks/actions';
export * from './requests/actions';
export * from './misc';
export { push, replace, go, goBack, goForward } from 'react-router-redux';Thus, any component can simply import whatever action creators it needs from a single source. At least, that would be the theory, unfortunately, we don't really have an ES6 environment but we are transpiling ES6 into ES5 to emulate one and dynamic re-exporting doesn't fully work. Ideally, we would just do:
export * from './projects';
export * from './tasks'
export * from './requests';
export * from './misc';
export { push, replace, go, goBack, goForward } from 'react-router-redux';
Because each of the index.js files for each of the sub-stores would either expose the action creators or re-export them from wherever they are actually declared. The transpiled code, however, doesn't cope with these two levels of re-exporting and it is better to import everything from the actual source. By the way, re-exporting all by using the * does not include the default export so there will be no reducers in the combined _store/actions file so only the named exports will be there, the action types and action creators.
# The client-side application
Now we can complete the picture of our client side application. We have seen the parts of the root index.js file that are related to the React components. Now that we have the store defined and the means to create it, we can look at the rest of that file.
const initialStateEl = document.getElementById('initialState');
let initialState = {};
if (initialStateEl) {
initialState = JSON.parse(initialStateEl.innerHTML);
}
export const store = createStore(browserHistory, initialState);In an isomorphic app, the client will receive the initial state of the store as a JSON string within some element. We try to get that element by its id and, if there is one, we read its contents and parse it.
Our imported createStore just needs that initialState, if there is one, and whatever flavor of history manager we want to use, in this case browserHistory which we imported from react-router. That gives us the store which we pass to Provider:
export default render((
<Provider store={store}>
<Router history={history}>
{components('/')}
</Router>
</Provider>
), dest);# Performance tools
if (process.env.NODE_ENV !== 'production') {
/* eslint-disable import/no-extraneous-dependencies, global-require */
window.Perf = require('react-addons-perf');
/* eslint-enable import/no-extraneous-dependencies, global-require */
}The React performance tools provides us with a profiler to determine where is our application wasting time. It doesn't make sense to install it in the production environment so we load it conditionally. We are not using ES6 import statement because the transpiled would hoist that request to the main scope, thus, it would not import it conditionally, it would always do so, adding up to the production bundle. That is why we have resorted to the require function which runs when and only if it is called. We have to turn off the warning of ESLint to tell it that we really mean to do that.
We save the performance tools into a Perf global variable so that we can use its commands from wherever we want in our code. The most important are:
Perf.start()andPerf.stop()to start and stop the capture of performance data. This can be called from the console or placed around any section of code we want to analyze.Perf.printWasted()shows in the console a nicely formatted table of all the components that were called but didn't actually change the DOM.
The shouldComponentUpdate method which our components inherit from React.Component is the main tool for us to prevent unnecessary re-renders. Most of our components are stateless so we don't have access to shouldComponentUpdate. On announcing stateless components the React team wrote:
In the future, we’ll also be able to make performance optimizations specific to these components by avoiding unnecessary checks and memory allocations.
That future is not there yet and stateless components, lacking shouldComponentUpdate to decide whether to render or not, always do render. That is why printWasted lists them quite often. If performance is an issue and until that future arrives, it might be a good idea to turn them into stateful components so they can benefit from shouldComponentUpdate.
For an isomorphic client, we also check whether the markup sent from the server has been preserved.
if (BUNDLE === 'client' && process.env.NODE_ENV !== 'production') {
if (
!dest ||
!dest.firstChild ||
!dest.firstChild.attributes ||
!dest.firstChild.attributes['data-react-checksum']
) {
console.error('Server-side React render was discarded. Make sure that your initial render does not contain any client-side code.'); // eslint-disable-line
}
}We set the BUNDLE constant when we pack the code with WebPack. It identifies the kind of bundle the code has been packed for. If it is a client bundle and we are not in production we check the data-react-checksum attribute on the first element within the container for our app. We do this after the app has been rendered. The server-side markup will contain the data-react-checksum, the markup created on the client side, does not. If there is still a data-react-checksum attribute, it means that the client accepted the server-side markup as valid and has not replaced it.
There is also a little addition for the Electron bundle () which we will see later on.
The index.jsx file is expected to run in the browser. That is why it uses window and document so freely. Those two globals would not be available on the server. Some of the files that index.jsx imports, such as createStore.js () may run on either side, that is why they cannot count on window or document to be there and have to check it first.